.png)

事故背景:
周五凌晨,核心交易系统突然告警。监控显示:响应时间(RT)从 30ms 飙升至超时,但 CPU 使用率(User%)却不足 5%
运维同学登录服务器一看,整个人都不好了:系统 Load Average(负载)竟然高达 120,而 CPU 却在“摸鱼”!既然 CPU 不忙,为什么系统动不了了?
本文将还原这次事故的排查全过程,并总结一套标准化的 Linux 高负载排查方法论。
01. 核心概念纠偏:Load 高 ≠ CPU 忙
在开始排查前,必须纠正一个常见的认知误区。
Linux 的Load Average定义是:单位时间内,处于“可运行状态(R)”和“不可中断睡眠状态(D)”的进程/线程总数。
如果把 CPU 比作收费站窗口:
CPU 忙(User/Sys 高):车辆都在排队过闸,窗口处理不过来。
I/O 忙(Wait 高):前面的车坏在闸口了(等磁盘 I/O),后面的车虽然能开,但全堵在路上。
Load 高:指的是**“堵在路上的车”的总数**。
本次事故的诡异之处在于:收费窗口没人(CPU 闲),但路上堵了 100 多辆车(Load 高)。这说明车子不是被“收费慢”堵住的,而是被别的东西卡住了。
02. 抽丝剥茧:排查四部曲
第一步:全局概览 (top) —— 找准病因
登录服务器,输入 top,第一眼先看头部信息:

关键指标解读:
Load Average:
120.54。对于一台 8 核服务器,这意味着负载超标 15 倍。且1分钟 > 5分钟,说明情况正在急剧恶化。%Cpu(s):
us(用户态) 3.2%:业务代码根本没在进行复杂计算。wa(iowait) 84.2%:红灯亮起!CPU 大部分时间都在等待 I/O 完成。
初步判断:这不是计算密集型问题,而是严重的 I/O 瓶颈 导致了大量线程积压。
第二步:确认磁盘压力 (iostat) —— 验证猜想
既然 CPU 在等 I/O,到底是在等谁?磁盘撑得住吗?
使用 iostat 查看磁盘详细指标:

输出结果:

证据确凿:
%util:100.00。磁盘vda的带宽已经被打满,没有任何喘息机会。await:320.5ms。正常的 SSD 响应应该在几毫秒,300ms 说明每个 I/O 请求都在排长队。
结论:某个进程正在疯狂写磁盘,导致磁盘瘫痪。
第三步:揪出元凶 (iotop) —— 定位进程
是谁在写?使用 iotop 抓现行:

输出结果:

锁定目标:
PID 为 15820 的 Java 业务进程。
第四步:深度溯源 (jstack) —— 还原真相
这是最关键的一步。很多人查到进程就结束了,但我们需要知道是哪行代码在闯祸。
我使用 jstack 导出线程堆栈:

堆栈显示了惊人的一致性:
几百个业务线程(Tomcat 线程池)虽然状态显示为 RUNNABLE,但都停留在同一个 Native 方法上:
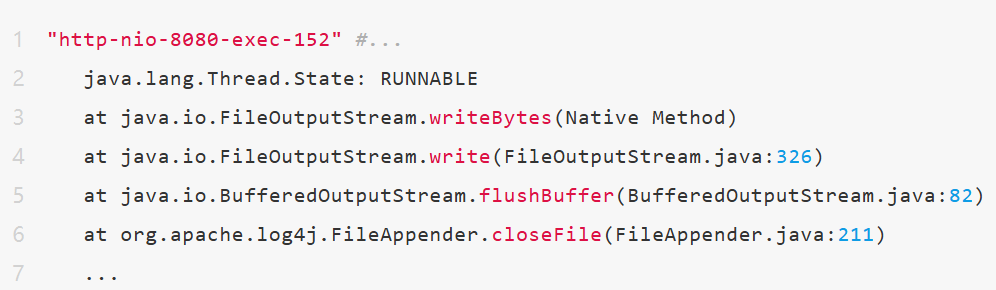
真相大白:
起因:一位开发为了排查 Bug,在线上开启了全局
DEBUG日志,且该服务配置了多文件输出(或使用了允许并发写入的日志配置)。瓶颈:巨量的日志瞬间打满了磁盘 IOPS。
堆积:进来的几百个用户请求,每个线程在执行到“写日志”这一行代码时,都在调用操作系统的
write接口。本质:虽然 Java 认为线程是
RUNNABLE(正在执行本地代码),但在操作系统看来,这些线程正卡在磁盘 I/O 队列中,处于D(Uninterruptible Sleep)状态。结果:Load = 正在运行 + 等待 I/O。几百个线程同时等磁盘,直接把 Load 顶到了 120。
03. 解决方案
紧急止血:
通过配置中心将日志级别动态调整回ERROR。磁盘写入量瞬间下降,I/O 释放,Load 在 1 分钟内回落到正常值。长期优化:
日志异步化:改用 Log4j2 / Logback 的
AsyncAppender,将日志写入放入内存队列,避免磁盘 I/O 直接阻塞业务线程。监控治理:增加对磁盘写入量和日志文件大小的监控报警。
制度规范:严禁在生产环境开启全局 DEBUG。
04. 总结:Load 高的“四象限”排查法
下次遇到 Load 飙升,不要慌,结合 top 的 CPU 数据,直接套用下表:
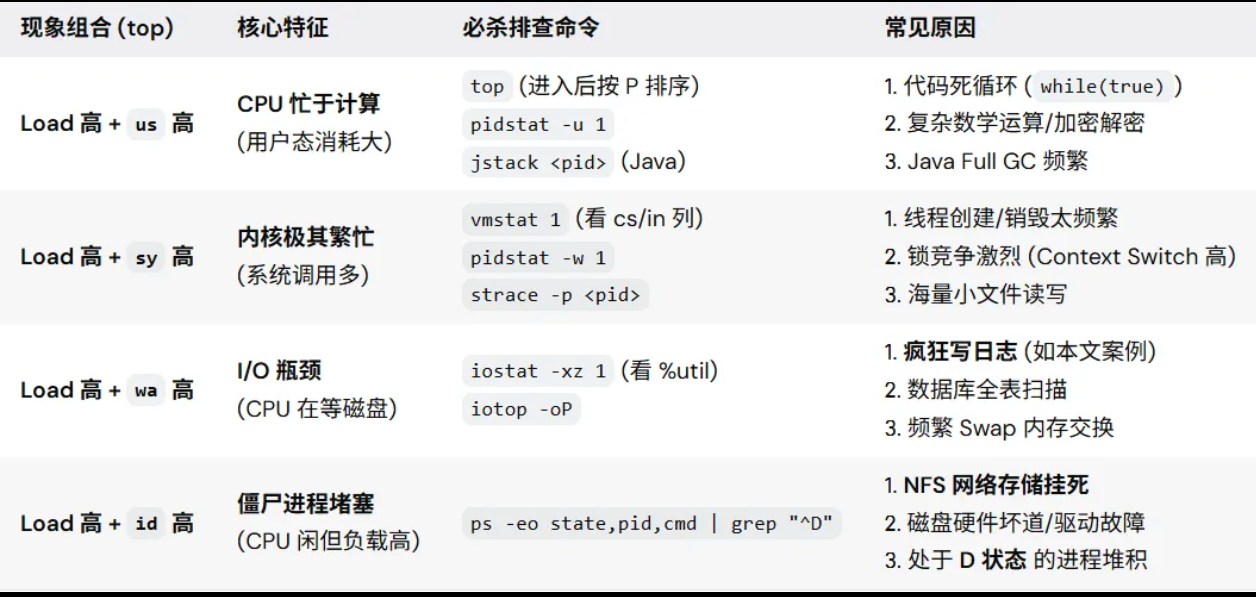
核心口诀:
Load 高,先看 CPU;
用户 (us) 高,查代码逻辑;
等待 (wa) 高,查磁盘读写;
系统 (sy) 高,查线程/锁;
啥都不高 (id),查 D 状态僵尸。
记住一句话:Load 高只是表象,CPU 使用率 (us/sy/wa) 才是指路明灯。
觉得有用的话,点个赞收藏,万一工作中也遇上了呢~
评论